200 OK! Error Handling in GraphQL
How to effectively model “errors” in your GraphQL schema

We all know how great GraphQL is when things go well, but what happens when things don’t go well?
How do we handle errors in GraphQL? How can we do it in a way that’s easy to understand?
Let’s start by running a simple GraphQL query:
{
user(username: "@ash") {
id
name
}
}we might get something like this:
{
"data": {
"user": {
"id": "268314bb7e7e",
"name": "Ash Ketchum"
}
}
}This is what we hope to see. But it’s not always smooth sailing. What happens when we make this same query but something goes wrong?
{
"data": {
"user": null
},
"errors": [
{ "path": [ "user" ],
"locations": [ { "line": 2, "column": 3 } ],
"extensions": {
"message": "Object not found",
"type": 2
}
}
]
}You get an error. And you’ll find it in the errors array. Canonically, this is where errors can be found in a GraphQL response.
There’s a lot to unpack here. We can see that there was an error that happened when we queried user. We can see that the error message was “Object not found”, and where it was located in our query.

The Problem
So, what’s wrong with this?
- All errors are treated the same
All errors end up in the errors array, no matter what kind of error they are. - It’s hard to know where the error came from
Our example was a simple query, but in more complex queries it’s harder to know where the error came from, especially if it’s, say, a list of items. - It’s hard for the client to know what errors to care about
Clients get all errors in the errors array, so clients can’t even query for errors. This means clients don’t know what cases there even are to handle, let alone which ones are important, which ones we can ignore, etc.
And, through all of this, the the response doesn’t make it easy for the client to display something useful to the user.
What is an error?
Before we really dig into this, we should really understand what an error is.
When we think of an “error”, we think of things like Internal Server Error, Deleted User, Bad Gateway, Unavailable in Country, Suspended User, etc.
But, it seems like all of these “errors” aren’t equivalent.
An Internal Server Error doesn’t seem at all the same as a Suspended User.
The same is true for a Bad Gateway versus Unavailable in Country. It seems like these are different types of errors.
Error Categories
When we start thinking of “errors” in this way, we can separate them into categories.

When we do this, we can see with things like Internal Server Error and Bad Gateway, something went wrong in servicing the request. So, these are definitely errors.
But in cases like Deleted User, Unavailable in Country, and Suspended User, nothing went wrong at all. They aren’t the result we expect most of the time, but they certainly aren’t errors. They’re results.
But let’s walk through why.
Errors
If we make a request to our GraphQL server, our server will make subsequent calls to our backends/services. If one of our services throws an exception, we’ll get a HTTP 500 (or equivalent) back, and something like “Server Error” will end up in our errors array.
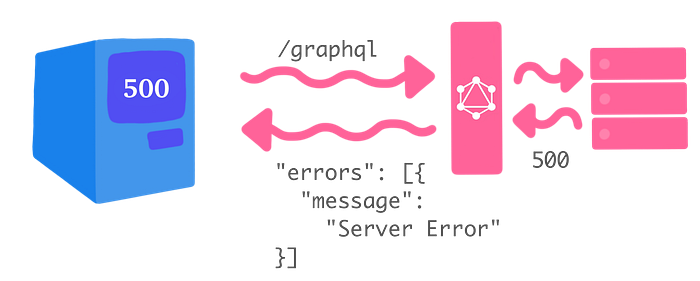
So, if we get an error, that means we couldn’t get the data we asked for, for some reason.
Alternative Results
For “alternative results”, this looks a little different. We have our client and our client hits the /graphql endpoint. When our graphql server calls out to our services, our services might send something back like Unavailable in Country or Suspended User.
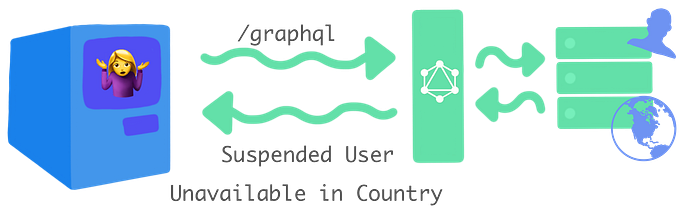
But these aren’t really errors…we got the data we requested. So really, our “alternative results” are just results.
For example, if we request a User we expect varying states of a User back. A User could be a normal User, but isn’t a Suspended User a User? And a Blocked User ? These are just different states of a User. So shouldn’t we be able to query for these if we care about them?
If we’ve learned anything about GraphQL it’s that you can query for what you care about.

Modeling Results in the GraphQL Schema
So how would we model this?
Say we have a User. We also have other results for what a User could be. These are all the possible results we have when we query for a User during normal operation.
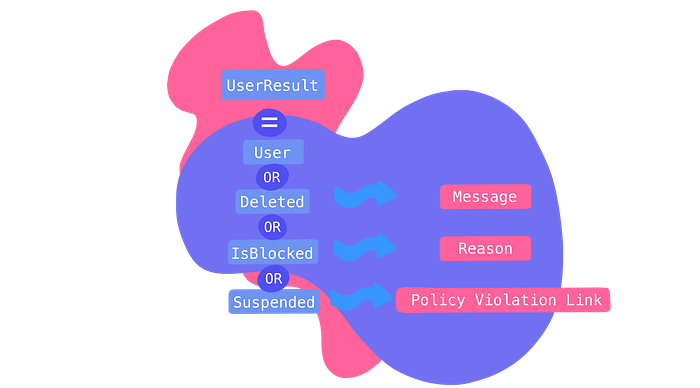
We can use a Union (perfect for representing which of several states!) to create a UserResult that encompasses all of these possible results.

In modeling this way, we can also customize what each result looks like depending on what ResultType we have.
For example, if we have a Deleted User, we could include a Message, or if our user is Suspended, we could include a Policy Violation Link.
In GraphQL SDL, it might look something like this:
type User {
id: ID!
name: String
}type Suspended {
reason: String
}type IsBlocked {
message: String
blockedByUser: User
}type UnavailableInCountry {
countryCode: Int
message: String
}
Which allows us to create a union type like this:
"User, or reason we can't get one normally"
union UserResult = User | IsBlocked | SuspendedClients only need to query for data they can use, so if they can’t handle a suspended user, they don’t query for it, and should also have some fallback behavior or a default case.
Now that these different states are in the schema (instead of implicit in an error), clients can easily see what cases exist to handle!
So when we make a query:
{
userResult(username: "@ash") {
__typename
... on User {
id
name
}
... on IsBlocked {
message
blockedByUser {
username
}
}
... on Suspended {
reason
}
}We get this as a result:
{
"data": {
"userResult": {
"__typename": "User",
"id": "268314bb7e7e",
"name": "Ash Ketchum"
}
}
}As we can see, we got a normal User response, and we know this is a User because of the __typename field (client libraries make this even easier to handle!).
But let’s say that this user is actually not available. If we run that same query again, we get this as a result:
{
"data": {
"userResult": {
"__typename": "IsBlocked",
"message": "User blocked: @ash",
"blockedByUser": {
"username": "@brock"
}
}
}
}We get an IsBlocked result instead, and all of the field we queried for on an IsBlocked response.
This is great because it means that:
- Results are customizable for each entity
A User will have different Results than other types, for example Tweet, will; we can add different Results and customize fields for each type. - We know where the error came from
We know exactly where our error comes from in the query (because it’s attached to the entity); it’s actually encoded in the schema. - The client decides what errors it cares about and what errors it can ignore
The client can query or not query for different Results, so it decides what’s important.

Complex Schema Structures
If we use this way of modeling our Results, we can imagine using Results for different entities within the same query.
So in addition to User and the results we defined previously, we can also define the following:
type ProfileImage {
id: ID!
value: String
}type Flagged {
reason: String
}type Hidden {
message: String
}
Given this, we can define our new Result Type:
"Image, or reason we can't get one normally"
union ImageResult = Image | Flagged | HiddenPutting this all together, we can now make a GraphQL query that includes both of the Result Types we defined:
{
userResult(username: "@ash") {
__typename
... on User {
id
name
profileImageResult {
__typename
... on Image {
id
}
... on Flagged {
reason
}
... on Hidden {
message
}
}
}
... on IsBlocked {
message
blockedByUser {
username
}
}
}We might get something like this:
{
"data": {
"userResult": {
"__typename": "User",
"id": "268314bb7e7e",
"name": "Ash Ketchum",
"profileImageResult": {
"__typename": "Image",
"id": "982642"
}
}
}
}Or, if the image we queried for is Copyrighted, we get something like this back instead:
{
"data": {
"userResult": {
"__typename": "User",
"id": "268314bb7e7e",
"name": "Ash Ketchum",
"profileImageResult": {
"__typename": "Flagged",
"reason": "Copyrighted image"
}
}
}
}In addition to having Results that are customizable for each entity, knowing where the error came from, and letting the client decide what errors it cares about and which it can ignore, this also means that
- “Errors” don’t cause failures for nested queries
We were able to query for two different ResultTypes, and when one “failed”, it didn’t cascade and cause the entire query to fail. - We can tune how verbose we want results to be
We can add result types to any entity we want (like we did with User and ProfileImage) or NOT! We get to decide. New result types get added to the schema explicitly instead of sneaking in silently as new kinds of errors. - We can more accurately represent our data
Our schema structure mirrors what our data looks like, which makes it easier to reason about.
And the nice thing is, you can customize this as much as you need to.
Results
Some things to take away when thinking about modeling “errors” in GraphQL, and just modeling in general:
- Not everything is an error
- Model your errors as errors, model your actual results as results
- Results are usually things you want to display
GraphQL intentionally does not prescribe how to model your schema, and the same goes for errors and results. It’s up to you to decide what describes your data best.

This is certainly not where modeling “errors” or results in the schema ends. How do we handle rate limiting? What about authentication or authorization errors? Do these things belong in the schema or not?
Sometimes there’s a clear answer, and sometimes there’s not! How you use your data determines how you should model it.
If you’d like to learn about all of this via video instead of a Medium post, you can watch it here, here, here, or here!

